****# 数据结构
# 前置知识
# 抽象数据类型(ADT)
抽象数据类型(abstract data type,ADT)是带有一组操作的一些对象的集合。诸如表、集合、图以及它们各自的操作一起形成的这些对象都可以被看做是抽象数据类型。
主要目的就是将抽象数据类型的具体实现与它们的功能分开。程序必须知道操作都做些什么(声明式),但是如果不知道如何去做那就更好。(命令式),比如可以使用封装好的栈来实现函数调用功能,而不需要知道栈是如何实现。
# 什么是表 ADT
ADT (abstract data type)表:A0,A1,A2,... An-1 的一般的表,这个表的大小是 N。我们将大小为 0 的特殊的表称为空表(empty list)。表中第一个元素是 A1,最后一个元素是 An。不定义 A1 的前驱元和 An 的后继元。元素Ai在表中的位置为 i。
表 ADT 上进行的操作的集合
PrintListMakeEmptyFind返回关键字首次出现的位置FindKth返回某个位置上的元素Insert/Delete从表的某个位置插入和删除某个关键字unioncontains
对象是表,通过 key 查找,数组也是表,通过数字索引。表可以通过数组、集合、图等实现,这里的表是一般意义上的抽象数据类型的集合。
- 普通的表:数组、栈、队列、链表(在 lua 中就一个数据结构 table 来进行对数组、哈希的实现)
- 数据库表:二维表格。
# 物理结构和逻辑结构
线性结构:一个接着一个链接起来。 非线性结构:多个分支。

# 数组
数组就像军队一样整整齐齐,有序。
几乎所有的编程语言都原生支持数组类型,因为数组是最简单的内存数据结构。数组存储一系列同一种数据类型的值。虽然在 JavaScript 里,也可以在数组中保存不同类型的值,但我们还是遵守最佳实践,避免这么做(大多数语言都没有这个能力)。
# 什么是数组
数组(Array)是有限个相同类型的变量所组成的有序集合,数组中的每一个变量被称为元素。数组是最为简单、最为常用的数据结构。
数组中的每一个元素都有着自己的下标,这个下标从 0 开始,一直到数组长度-1。
数组的另一个特点,是在内存中顺序存储,因此可以很好地实现逻辑上的顺序表`。
数组在内存中的顺序存储,具体是什么样子呢?
内存是由一个个连续的内存单元组成的,每一个内存单元都有自己的地址。在这些内容单元中,有些被其他数据占用了,有些是空闲的。
数组中的每一个元素,都存储在小小的内容单元中,并且元素之间紧密排列。既不能打乱元素的存储顺序,也不能跳过某个存储单元进行存储。
const insert = (arr, element, index) => {
// 判断下标是否超出范围
if (index < 0 || index >= arr.length) {
throw new RangeError("超出数组实际元素范围!")
}
// 从右向左循环,将元素逐个向右挪一位
for (let i = arr.length -1; i >= index; i--) {
arr[i+1] = arr[i]; // // js 语言会默认新建一个空的,不会有溢出的情况,否则需要扩容数组()
}
// 腾出的位置放入新元素
arr[index] = element;
return arr;
}
const deleteEle = (arr, index) => {
// 判断下标是否超出范围
if (index < 0 || index >= arr.length) {
throw new RangeError("超出数组实际元素范围!")
}
// 腾出的位置放入新元素
const deleteEle = arr[index];
// 从左向右循环,将元素逐个向左挪一位
for (let i = index; i <= arr.length -1; i++) {
arr[i] = arr[i+1]; // // js 语言会默认新建一个空的,不会有溢出的情况,否则需要扩容数组()
}
return deleteEle;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
利用数组模拟栈和队列:
Tip:通过 push 和pop方法,就能用数组来模拟栈。
let numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
console.log('原数组', numbers);
numbers.push(11);
console.log('在数组末尾插入11', numbers)
numbers.pop();
console.log('在数组末尾删除一个元素', numbers)
2
3
4
5
6
7
8
Tip: 通过 shift 和 unshift 方法,我们就能用数组模拟基本的队列数据结构。
let numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
console.log('原数组', numbers);
numbers.unshift(-2)
console.log('在数组开头插入-2', numbers)
numbers.shift();
console.log('在数组开头删除一个元素', numbers)
2
3
4
5
6
7
8
# 数组的优势和劣势
优势:
- 数组拥有非常高效的随机访问能力,只要给出下标,就可以用常量时间找到对应元素。有一种高效查找元素的算法叫做二分查找,就是利用了数组的这个优势。 劣势:
- 体现在插入和删除元素方面。由于数组元素连续紧密地存储在内存中,插入、删除元素都会导致大量元素被迫移动,影响效率。
总的来说,数组所适合的是读操作多、写操作少的场景。
# 链表
为了避免插入和删除的线性开销,我们需要保证表可以不连续存储,否则表的每个部分都可能需要整体移动。
# 简单链表
链表由一系列节点组成,这些节点不必在内存中相连。每一个节点均含有表元素和到包含该元素后继元的链(link)。我们称之为 next 链。最后一个单元的 next 链引用 null。(定义用例)
# 什么是双向链表
双向链表比单向链表稍微复杂一些,它的每一个节点除了拥有 data 和 next 指针,还拥有指向前置节点的 prev 指针。

文章的上一页和下一页,使用链表实现一个分页组件。
# 链表的存储方式
如果说数组在内存中的存储方式是顺序存储,那么链表在内存中的存储方式则是随机存储。
什么叫随机存储?
数组在内存中占用了连续完整的存储空间。而链表则采用了见缝插针的方式,链表的每一个节点分布在内存的不同位置,依靠 next指针关联起来。这样可以灵活有效地利用零散的碎片空间。
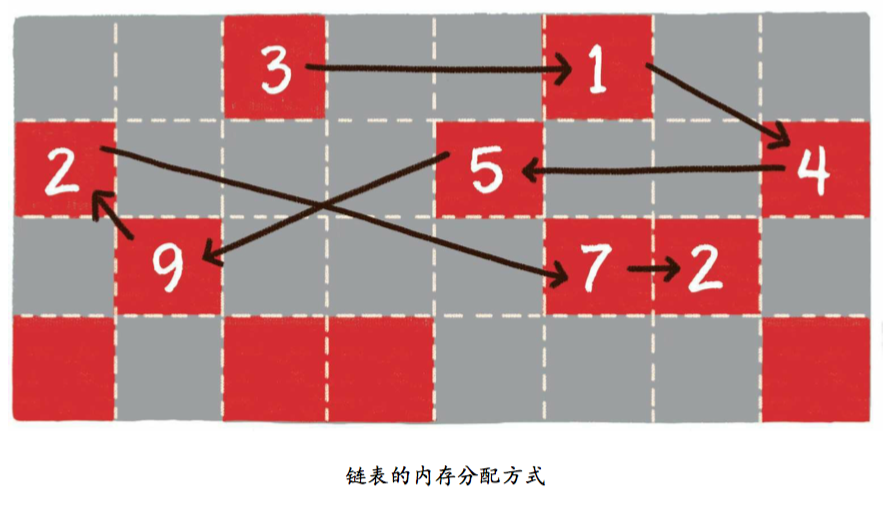
# 链表的基本操作
# 查找节点
根据 next 指针一步步移动查找。
# 更新节点
查找到对应的节点进行更新。
# 插入节点
与数组类似,链表插入节点时,同样分为 3 种情况。
- 尾部插入
- 头部插入
- 中间插入
尾部插入,把最后一个节点的 next 指针指向新插入的节点即可。
头部插入,可以分成两个步骤。
- 第 1 步,把新节点的 next 指针指向原先的头节点。
- 第 2 步,把新节点变为链表的头节点。
中间插入,同样分为两个步骤:
- 第 1 步,新节点的 next 指针,指向插入位置的节点。
- 第 2 步,插入位置前置节点的 next 指针,指向新节点。
只要内存空间允许,能够插入链表的元素是无穷无尽的,不需要像数组那样考虑扩容的问题。
# 删除元素
链表的掸
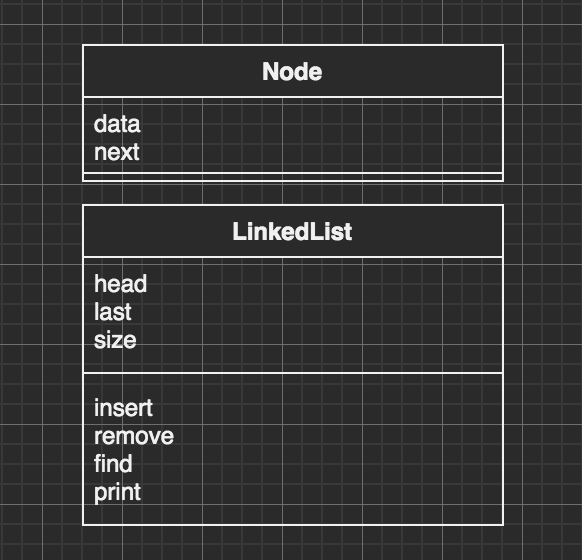
# 实现
# 版本一
using System;
namespace DataStructures.Lists
{
/*
* 思路:位置
*/
public class Node
{
public Node next;
public int data;
public Node(int data)
{
this.data = data;
}
}
public class SingleLinkedList
{
private Node head; // 头指针
private Node last; // 尾指针,为了尾部插入的方便所用
private int size; // 链表实际长度
public SingleLinkedList()
{
}
/*
* 链表插入节点
*/
public Node Insert(int data, int index)
{
if (index < 0 || index > size)
{
throw new IndexOutOfRangeException("超出链表节点范围");
}
// 新节点
Node insertedNode = new Node(data);
// 空链表
if (size == 0)
{
head = insertedNode;
last = insertedNode;
}
// 插入头部
else if (index == 0)
{
insertedNode.next = head; // 移动旧的头部节点 next 指向新节点
head = insertedNode; // 改变头部指针指向为新节点
}
// 插入尾部
else if (size == index)
{
last.next = insertedNode; // 移动旧的尾部节点 next 指向新节点
last = insertedNode; // 改变尾部指针指向为新节点
}
// 插入中间
else
{
// 寻找 index 上一个节点
Node prevNode = Get(index - 1);
// 插入
insertedNode.next = prevNode.next; // 链接新节点到原来的节点
prevNode.next = insertedNode; // 改变上一个节点的 next 指向
}
size++;
return insertedNode;
}
/*
* 删除节点
* @param {int} index
* @return 返回删除的节点 {Node} s
*/
public Node Remove(int index)
{
if (index < 0 || index > size)
{
throw new IndexOutOfRangeException("超出链表节点范围");
}
Node removeNode;
// 删除头部节点
if (index == 0)
{
removeNode = head;
head = head.next;
}
// 删除尾部节点
else if (index == size)
{
Node prevNode = Get(index - 1);
removeNode = prevNode.next;
prevNode.next = removeNode.next;
last = prevNode; // 移动 last 指针
}
// 删除中间节点
else
{
Node prevNode = Get(index - 1);
Node nextNode = prevNode.next.next;
removeNode = prevNode.next;
prevNode.next = nextNode;
}
size--;
return removeNode;
}
/*
* 查找节点
*/
public Node Get(int index)
{
if (index < 0 || index >= size)
{
throw new IndexOutOfRangeException("超出链表节点范围");
}
Node temp = head;
for (int i = 0; i < index; i++)
{
temp = temp.next;
}
return temp;
}
public void Print()
{
Node temp = head;
while (temp != null)
{
Console.Write(temp.data);
temp = temp.next;
}
}
public static void Main() { }
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
使用
using System;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using DataStructures.Lists;
namespace UnitTest.DataStructuresTests
{
[TestClass]
public class SingleLinkedListDemoTest
{
public SingleLinkedListDemoTest()
{
}
[TestMethod]
public void TestMethod()
{
SingleLinkedList singleLinkedList = new SingleLinkedList();
singleLinkedList.Insert(3, 0);
singleLinkedList.Insert(7, 1);
singleLinkedList.Insert(9, 2);
singleLinkedList.Insert(5, 3);
singleLinkedList.Insert(6, 1);
singleLinkedList.Remove(0);
singleLinkedList.Print();
Assert.AreEqual(singleLinkedList.Get(0).data, 6);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 数组 vs 链表
# 散列(hash)表
一个散列(hash)表示一个集合,其中每个值都与一个键相关联;一些编程语言把这种数据结构叫做映射(map)、字典(dictionary) 或者关联数组(associative array)。一个散列表字面量写成大括号里用逗号分割的键值对的列表。
# 栈模型
栈是一种遵从后进先出(LIFO)原则的有序集合。新添加或待删除的元素都保存在栈的同一端,称作栈顶,另一端就叫栈底。在栈里,新元素都靠近栈顶,旧元素都接近栈底。(用例定义)。
在现实生活中也能发现很多栈的例子。例如,下图里的一摞书或者餐厅里叠放的盘子。

栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈的顶(top)。对栈的基本操作有 push(进栈) 和 pop(出栈),前者相当于插入,后者则是删除最后插入的元素。最后插入的元素可以通过使用 top 例程(指针)在执行 pop 之前进行考查。对空栈进行的 pop 或 top 一般被认为是栈 ADT 中的一个错误。另一方面,当运行 push 时空间用尽则是一个实现限制,但不是 ADT 错误。
# 栈的实现

# 利用链表实现一个栈
使用自带的 LinkedList
# 利用数组创建一个栈
JS 实现
// LIFO:只能用 push, pop 方法添加和删除栈中元素,满足 LIFO 原则
class Stack {
constructor() {
this.items = [];
}
/**
* @description 向栈添加元素,该方法只添加元素到栈顶,也就是栈的末尾。
* @param {*} element
* @memberof Stack
*/
push(element) {
this.items.push(element);
}
/**
* @description 从栈移除元素
* @returns 移出最后添加进去的元素
* @memberof Stack
*/
pop() {
return this.items.pop();
}
/**
* @description 查看栈顶元素
* @returns 返回栈顶的元素
* @memberof Stack
*/
peek() {
return this.items[this.items.length - 1];
}
/**
* @description 检查栈是否为空
* @returns
* @memberof Stack
*/
isEmpty() {
return this.items.length === 0;
}
/**
* @description 返回栈的长度
* @returns
* @memberof Stack
*/
size() {
return this.items.length;
}
/**
* @description 清空栈元素
* @memberof Stack
*/
clear() {
this.items = [];
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 用栈解决问题
栈的实际应用非常广泛(只要满足 LIFO 规则的算法都可以使用栈来解决问题)。在回溯问题中,它可以存储访问过的任务或路径、撤销的操作。Java 和 C# 用栈来存储变量和方法调用,特别是处理递归算法时,有可能抛出一个栈溢出异常。
# 利用栈解决十进制转二进制的问题。
/**
* 把十进制转换成二进制。
* @param {*} decNumber 十进制
*/
export function decimalToBinary(decNumber) {
const remStack = new Stack();
let number = decNumber; // 十进制数字
let rem; // 余数
let binaryString = '';
while (number > 0) {
// 当结果不为0,获得一个余数
rem = Math.floor(number % base);
remStack.push(rem); // 入栈
number = Math.floor(number / base);
}
while(!remStack.isEmpty()) {
binaryString += remStack.pop().toString();
}
return binaryString;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 代码运行方式——调用栈
调用栈,表示函数或子例程像堆积木一样存放,以实现层层调用。 下面以一段 Java 代码为例:
class Student {
int age;
String name;
public Student(int Age, String Name) {
this.age = Age;
setName(Name);
}
public void setName(String Name) {
this.name = Name;
}
}
public class Main {
public static void main(String[] args) {
Student s;
s = new Student(23, "Jonh")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
上面这段代码运行的时候,首先调用 main 方法,里面需要生成一个 Student 的实例,于是又调用 Student 构造函数。在构造函数中,又调用到 setName 方法。
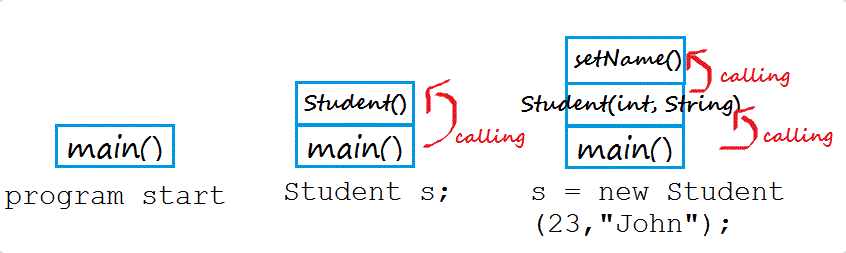
这三次调用像积木一样堆起来,就叫做“调用栈”。程序运行的时候,总是先完成最上层的调用,然后将它的值返回到下一层调用。直至完成整个调用栈,返回最后的结果。
原理大概:
- 调用
main方法,这个时候需要调用Student构造函数,把这个位置A作为return地址存入栈中。 - 这个时候调用并进入
Student构造函数内部,遇到SetName()方法,把这里的位置B作为return地址存入栈中记录下来存入栈中。 - 这时调用并进入
setName()方法内部执行完毕后,之后从栈中拿出B地址,返回到Student函数内部继续执行。 Student函数执行完毕后,然后从栈中继续拿出A地址,进入到一开始的main函数内部执行,至此完毕。
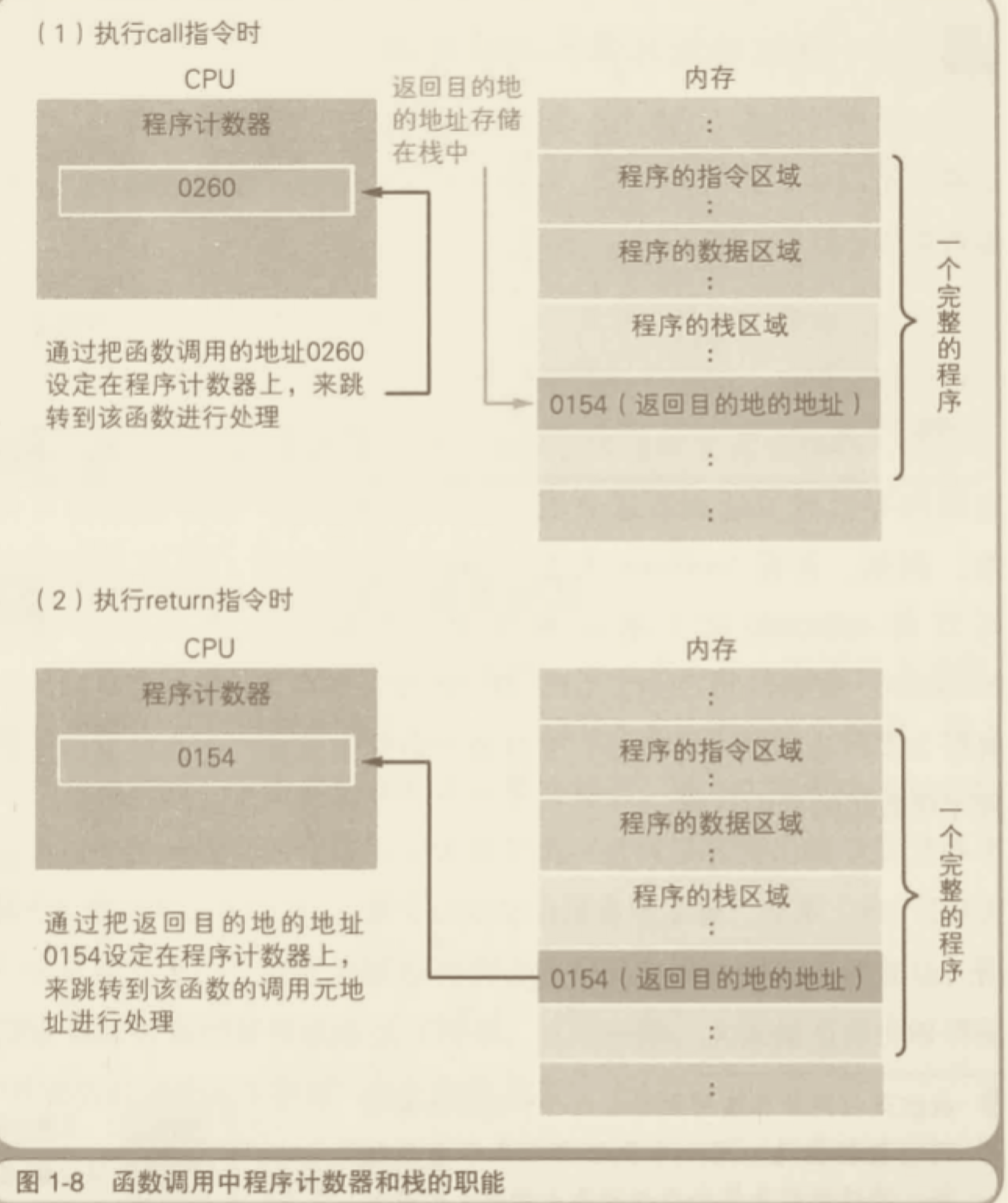
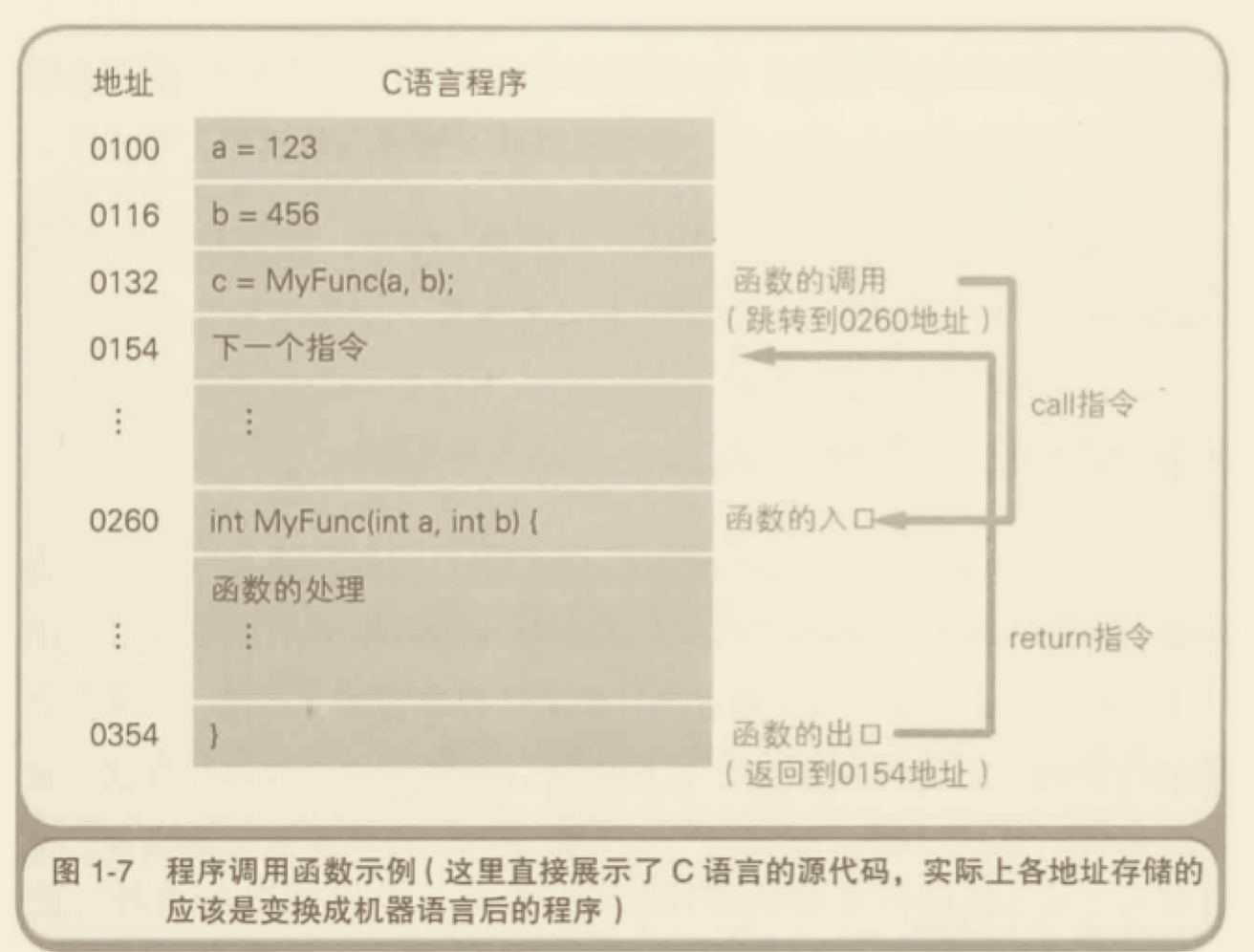
# 内存区域
程序运行的时候,需要内存空间存放数据。一般来说,系统会划分出两种不同的内存空间:一种是叫做 stack (栈),另一种叫做 heap(堆)。一般来说,每个线程分配一个 stack,每个进程分配一个 heap,也就是说,stack 是线程独占的,heap 是线程共享的。此外,stack 创建的时候,大小是确定的,数据超过这个带下,就发生 stack overflow 错误。而 heap 的大小是不确定的,需要的话可以不断增加。
栈由系统自动分配释放,存放函数的参数值和局部变量的值等。
堆一般由程序员分配释放,若程序员不释放,程序结束时可能由 OS 回收。
根据上面这些区别,数据存放的规则是:只要是局部的、占用空间确定的数据,一般都存放在 stack 里面,否则就放在 heap 里面。请看下面这段代码:
public void Method1() {
int i = 4;
int y = 2;
class1 cls1 = new class1();
}
2
3
4
5
上面的代码的 Method1 方法,共包含了三个变量:i,y 和 cls1。其中,i 和 y 的值是整数,内存占用空间是确定,而且是局部变量,只用在 Methods1 区块之内,不会用于区块之外。cls1 也是局部变量,但是类型为指针变量,指向一个对象的实例。指针变量占用的大小是确定的(这里存储的是地址),但是对象实例以目前的信息无法确知所占用的内存空间大小。
这三个变量和一个对象实例在内存中的存放方式如下:
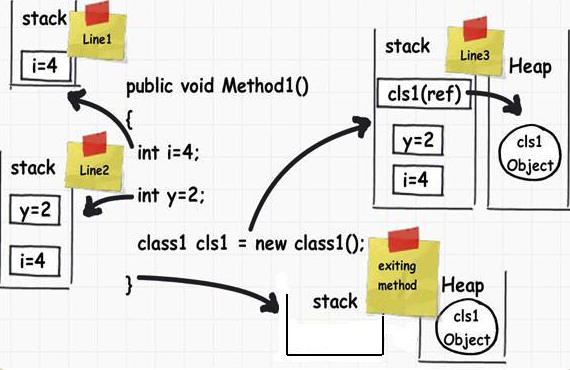
从上图可以看到,i、y 和 cls1 都存放在 stack,因为它们占用内存空间都是确定的,而且本身也属于局部变量。但是,cls1 指向的对象实例存放在 heap,因为它的大小不确定。
接下来的问题是,当 Method1 方法运行结束,会发生什么事?
回答是整个 stack 被清空,i、y 和 cls1 这三个变量消失,因为它们是局部变量,区块一旦运行结束,就没必要再存在了。而 heap 之中的哪个对象实例继续存在,直到系统的垃圾清理机制(garbage collector)将这块内存回收。因此,一般来说,内存泄漏都发生在 heap,即某些内存空间不再被使用了,却因为种种原因,没有被系统回收。
# 综合分析一段 JavaScript 代码(内存区域+调用栈)
# 递归算法中,变量和方法是如何入栈的,为什么有爆栈?或者说栈溢出?
- 调用栈
每当一个函数被一个算法调用时,该函数会进入调用栈的顶部。当使用递归时,每个函数调用都回堆叠在调用栈的顶部,这是因为每个调用都可能依赖前一个调用的结果。
/**
* 递归阶乘
* @param {*} n
*/
function factorial(n) {
console.trace()
if (n === 1 || n === 0) { // 基线条件
return 1;
}
return n * factorial(n -1); // 递归调用
}
console.log('factorial(3) :', factorial(3));
2
3
4
5
6
7
8
9
10
11
12
我们可以用浏览器看到调用栈的行为,如下图所示
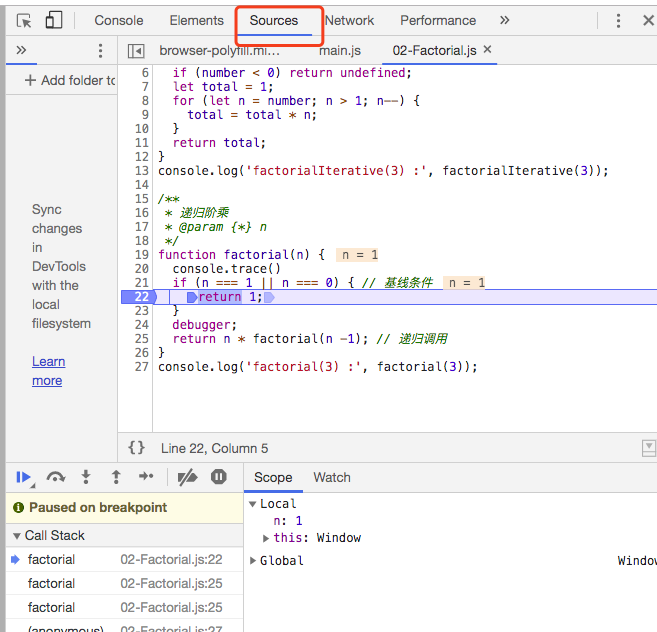
通过 debugger 可以看到每一次函数在推入栈,直接当 factorial(1) 被调用时,我们能在控制台得到下面的结果。
factorial @ 02-Factorial.js:20
factorial @ 02-Factorial.js:25
factorial @ 02-Factorial.js:25
2
3
当 factorial(1) 返回 1 时,调用栈开始弹出调用,返回结果,直到 3 * factorial(2) 被计算。
- JavaScirpt 调用栈大小的限制
如果忘记加上用以停止函数递归调用的基线条件,会发生什么呢?递归并不会无限地执行下去,浏览器会抛出错误,也就是所谓的栈溢出错误。(stack overflow error)。
每个浏览器都有自己的上限,可用以下代码测试。
// 测试浏览器的栈溢出错误,即超过最大调用栈
let i = 0;
function recursiveFn() {
i++;
recursiveFn();
}
try {
recursiveFn();
} catch (ex) {
console.log('i = ' + i + 'error: ' + ex);
}
2
3
4
5
6
7
8
9
10
11
在 Chrome 78 中,该函数执行了 15689 次,之后抛出错误 RangeError: Maximum call stack size exceeded(超限错误:超过最大调用栈大小)。
解决方案是可以使用尾递归优化。
# 队列
# 队列数据结构
队列是遵循先进先出(FIFO,也称为先来先服务)原则的一组有序的项。队列在尾部添加新元素,并从顶部移除元素。最新添加的元素必须排在队列的末尾。
在现实中,最常见的队列的例子就是排队。

在电影院、自助餐厅、杂货店收银台,我们都会排队。排在第一位的人会先接受服务。 在计算机科学中,一个常见的例子就是打印队列。比如说,我们需要打印五份文档。我们会打开每个文档,然后点击打印按钮。每个文档都会被发送至打印队列。第一个发送到打印队列的文档会首先被打印,以此类推,直到打印完所有文档。
# 创建队列
export default class Queue {
constructor() {
this.count = 0; // 控制队列的大小
this.lowestCount = 0; // 用于追踪第一元素,便于从队列前端移除元素
this.items = {}; // 用对象存储我们的元素
}
/**
* 向队列添加元素
* 该方法负责向队列添加新元素,新的项只能添加到队列末尾。
* @param {*} element
*/
enqueue(element) {
this.items[this.count] = element;
this.count++;
}
/**
* 从队列移除元素
*/
dequeue() {
if (this.isEmpty()) {
return undefined;
}
const result = this.items[this.lowestCount]; // 暂存队列头部的值,以便改元素被移除后将它返回
delete this.items[this.lowestCount];
this.lowestCount++; // 属性+ 1
return result;
}
/**
* 查看队列头元素
*/
peek() {
if (this.isEmpty()) {
return undefined;
}
return this.items[this.lowestCount];
}
/**
* 检查队列是否为空并获取它的长度
*/
isEmpty() {
return this.count - this.lowestCount === 0; // 要计算队列中有多少元素,我们只需要计算 count 和 lowestCount 之间的差值
}
/**
* 计算队列中有多少元素
*/
size() {
return this.count - this.lowestCount;
}
/**
* 清空队列
* 要清空队列,我们可以调用 dequeue 方法直到它返回 undefined,也可以简单地将队列中的舒心值重设为和构造函数的一样。
* @memberof Queue
*/
clear() {
this.items = {};
this.count = 0;
this.lowestCount = 0;
}
toString() {
if (this.isEmpty()) {
return '';
}
let objString = `${this.items[this.lowestCount]}`;
for (let i = this.lowestCount + 1; i < this.count; i++) {
objString = `${objString},${this.items[i]}`
}
return objString;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# 双端队列数据结构
# 使用队列和双端队列来解决问题
# 循环队列——击鼓传花游戏
import Queue from "../data-structures/queue"
/**
* 模拟击鼓传花
* 循环队列。在这个游戏中,孩子们围成一个圆圈,把花尽快传递给旁边的人。某一时刻传花停止,这个时候花在谁手上,谁就退出圆圈,结束游戏。
* 重复这个过程,直到只剩一个孩子(胜者)。
* @export
* @param {*} elementsList 要入列的元素
* @param {*} num // 达到给定的传递次数。 // 可以随机输入
*/
export default function hotPotato(elementsList, num) {
const queue = new Queue();
const elimitatedList = [];
for (let i = 0; i < elementsList.length; i++) {
queue.enqueue(elementsList[i]);
}
while (queue.size() > 1) {
// 循环队列,给定一个数字,然后迭代队列。从队列开头移除一项,再将其添加到队列末尾,模拟击鼓传花。
// 一旦达到给定的传递次数,拿着花的那个人就被淘汰了。(从队列中移除)
for (let i = 0; i < num; i++) {
queue.enqueue(queue.dequeue());
}
elimitatedList.push(queue.dequeue());
}
return {
elimitated: elimitatedList,
winner: queue.dequeue()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# JavaScript 任务队列
当我们在浏览器中打开标签时,就会创建一个任务队列。这是因为每个标签都是单线程处理所有的任务,成为事件循环。浏览器要负责多个任务,如渲染 HTML、执行 JavaScript 代码、处理用户交互(用户输入、鼠标点击等)、执行和处理异步请求。
# 树
# 二叉树
# 二叉查找树
# 图
# 二叉堆和堆排序
# 二叉堆
堆(Heap)是计算机科学一类特殊的数据结构的统称,堆通常是一个可以看作一颗完全二叉树的数组对象。 二叉堆是一种特殊的二叉树,有一以下两个特性。
- 它是一颗完全二叉树,表示树的每一层都有左侧和右侧子节点。(除了最后一层的叶节点),并且最后一层的叶节点尽可能都是左侧子节点,这叫做结构特性。
- 二叉堆不是最小堆就是最大堆。最小堆允许你快速导出树的最小值,最大堆允许你快速导出树的最大值。所有的节点都大于等于(最大堆)或小于等于(最小堆)每个它的子节点。这叫做堆特性。
- 在二叉堆中,每个子节点都要大于等于父节点(最小堆)或小于等于父节点(最大堆)。 将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。 堆是非线性数据结构,相当于一维数组,有两个直接后继。
# 创建最小堆类
使用一个数组,通过索引值检索父节点、左侧和右侧子节点的值。
import { defaultCompare, Compare, swap } from '../util'
/**
* 最小堆类
* 完全二叉树,根节点最小的堆叫做最小堆
* 在二叉堆中,每个子节点都要大于等于父节点
* @export
* @class MinHeap
*/
export class MinHeap {
constructor(compareFn = defaultCompare) {
this.compareFn = compareFn;
this.heap = []; // 使用数组来存储数据,通过索引值检索父节点、左侧和右侧子节点的值。
}
getLeftIndex(index) {
return 2 * index + 1;
}
getRightIndex(index) {
return 2 * index + 2;
}
getParentIndex(index) {
if (index === 0) {
return undefined;
}
return Math.floor((index - 1) / 2)
}
/**
* 向堆中插入值
* 指将值插入堆的底部叶节点(数组的最后一个位置)
* @param {*} value
* @memberof MinHeap
*/
insert(value) {
if (value !== null) {
this.heap.push(value);
this.siftUp(this.heap.length - 1); // 将这个值和它的父节点进行交换,直到父节点小于这个插入的值。
return true;
}
return false;
}
/**
* 上移操作,维护堆的结构
* 将这个值和它的父节点进行交换,直到父节点小于这个插入的值。
* @param {*} index
* @memberof MinHeap
*/
siftUp(index) {
let parent = this.getParentIndex(index); // 获得父节点的索引
while( index > 0 && this.compareFn(this.heap[parent], this.heap[index]) === Compare.BIGGER_THAN) {
swap(this.heap, parent, index);
index = parent; // 往上替换
}
}
size() {
return this.heap.length;
}
isEmpty() {
return this.size() === 0;
}
/**
* 从堆中找到最小值或最大值
* 在最小堆中,最小值总是位于数组的第一个位置(堆的根节点)
* @memberof MinHeap
*/
findMinimum() {
return this.isEmpty() ? undefined : this.heap[0];
}
/**
* 移除最小值表示移除数组中的第一个元素(堆的根节点)。
* 在移除后,我们将堆的最后一个元素移动至根部并执行 siftDown 函数,表示我们将交换元素直到堆的结构正常。
* @memberof MinHeap
*/
extract() {
if(this.isEmpty()) {
return undefined;
}
if (this.size() === 1) {
return this.heap.shift();
}
const removedValue = this.heap.shift();
this.siftDown(0);
return removedValue;
}
/**
* 下移操作,维护堆的结构
* @param {*} index 移除元素的位置
* @memberof MinHeap
*/
siftDown(index) {
let element = index; // 将 index 复制到 element 变量中
const left = this.getLeftIndex(index);
const right = this.getRightIndex(index);
const size = this.size();
// 如果元素比左侧节点要小,且 index 合法。
if (left < size && this.compareFn(this.heap[element], this.heap[left]) === Compare.BIGGER_THAN) {
element = left;
}
// 如果元素比右侧节点要小,且 index 合法。
if (right < size && this.compareFn(this.heap[element], this.heap[right] === Compare.BIGGER_THAN)) {
element = right;
}
if (index !== element) {
swap(this.heap, index, element);
this.siftDown(element); // 向下移动
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
# 堆的应用
在程序中,堆用于动态分配和释放程序中所使用的对象。在以下情况中调用堆操作:
- 事先不知道程序所需对象的数量和大小。
- 对象太大,不适合使用堆栈分配器。
关于堆、栈、队列的可视化描述:

# 参考资料
- 《小灰的算法之旅》
- 给数组扩容的几种方式